
robots.txt 是一个搜索引擎爬虫协议文件,它的作用是告诉搜索引擎蜘蛛您网站的哪些页面可以被抓取,哪些页面不可以被抓取。robots.txt 是一种遵循漫游器排除标准的纯文本文件,由一条多多条的规则组成,没跳规则可以禁止或允许特定的搜索引擎蜘蛛抓取网站的制定文件路径下的文件。如果你没有进行设置,则默认所有文件都允许抓取。
robots.txt 是一个搜索引擎爬虫协议文件,它的作用是告诉搜索引擎蜘蛛您网站的哪些页面可以被抓取,哪些页面不可以被抓取。robots.txt 是一种遵循漫游器排除标准的纯文本文件,由一条多多条的规则组成,没跳规则可以禁止或允许特定的搜索引擎蜘蛛抓取网站的制定文件路径下的文件。如果你没有进行设置,则默认所有文件都允许抓取。
robots.txt 规则包括了:
User-agent:爬虫的用户代理(UA) 标识符,可在此处查看。
Allow:允许访问抓取。
Disallow:禁止访问抓取。
Sitemap:站点地图。不限制条数,你可以添加数条 sitemap 的链接。
#:注释行。
下面是一个包含两条规则的简单 robots.txt 文件:
User-agent: YisouSpider
Disallow: /
User-agent: *
Allow: /
Sitemap: /sitemap.xml
User-agent: BaiduSpider 行的意思就是:针对用户代理为“YisouSpider”(一搜搜索引擎爬虫)的规则,同样可以设置为 bingbot(必应)、Googlebot(谷歌)等等。其他搜索引擎爬虫的代理名字可在此处查看。
Disallow: / 的意思是“禁止访问抓取全部内容”。
User-agent: 行的意思就是:针对全部用户代理(* 为通配符)的规则。其他所有用户代理均可抓取整个网站。不指定这条规则也无妨,结果是一样的;默认行为是用户代理可以抓取整个网站。
Sitemap: 行的意思是:该网站的站点地图文件路径为 /sitemap.xml。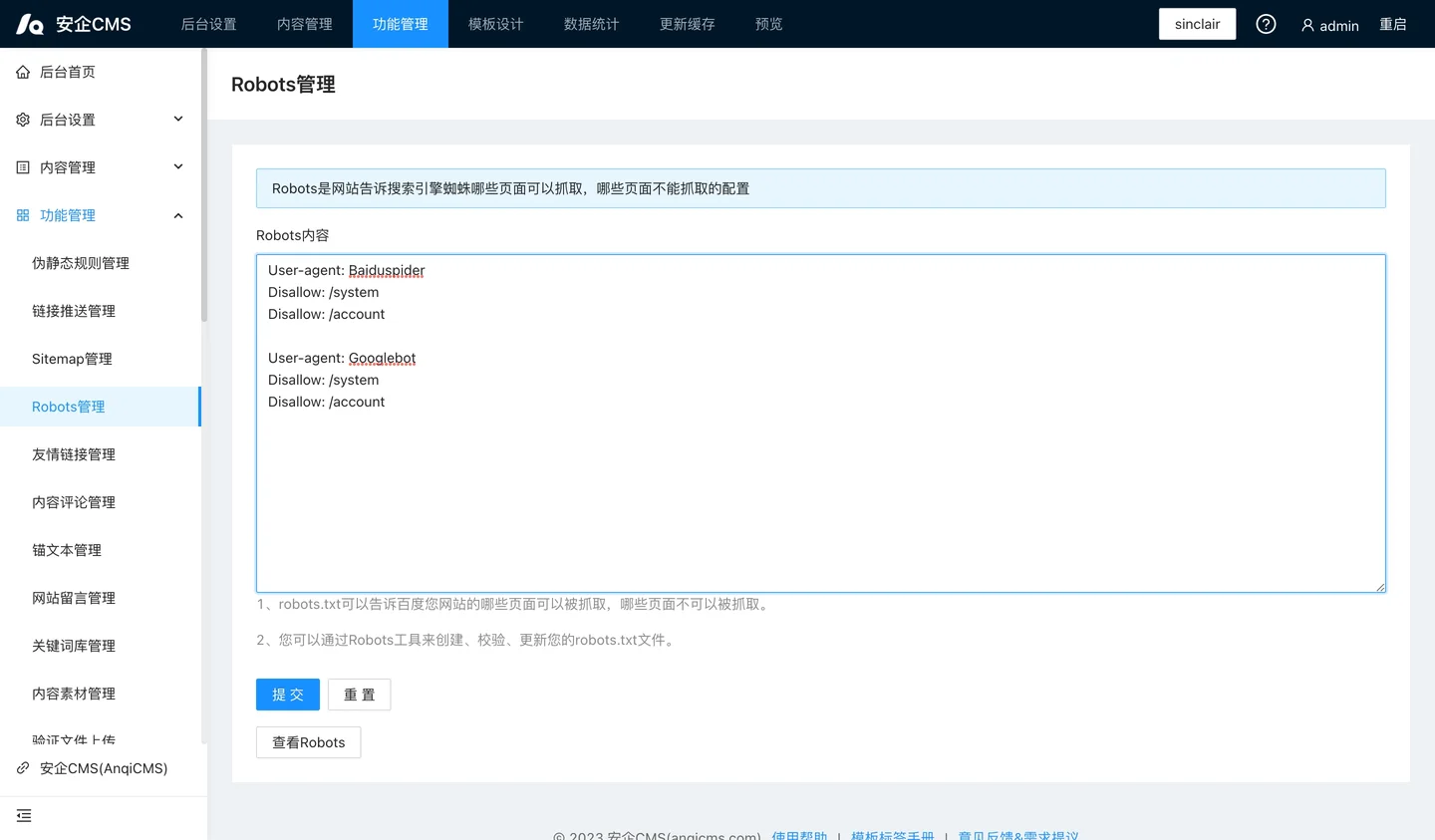

Sitemap 是网站的地图,通过集中的链接方式,可以将分类、文章内容、页面、tag等集中在一起展示,方便搜索引擎蜘蛛可以快速的爬取网站的全部公开内容。Sitemap 网站地图是网站进行SEO的重要组成部分,扩大网站在搜索引擎的曝光度。

链接推送功能支持自动将网站新发布、更新的内容,实时的推送给搜索引擎,让搜索引擎及时发现网站更新的内容,促进网站收录。搜索引擎推送功能支持百度搜索、必应搜索的主动推送,其他搜索引擎虽然没有主动推送功能,但部分搜索引擎依然可以使用JS推送。

友情链接,也称为网站交换链接,是指在自己的网站上放对方网站的链接,也属于外链的一种形式。做好友情链接可以提升你的网站的权重和你的网站的关键词排名。友情链接比普通的外链对于网站的排名来说更有利。
